CV Chat - OpenAI integration
February 25, 2025

Introduction
If you’ve already read the main journey page detailing the evolution of the CV Chat component, this page dives into the technical details behind the system. Here, I explain the shared infrastructure and core workflow—from data preparation to delivering AI-powered responses—and how an adapter pattern enables seamless switching between different AI providers (such as OpenAI and Flowise). For specifics on the AWS Bedrock implementation, please visit the dedicated AWS Bedrock Implementation page .
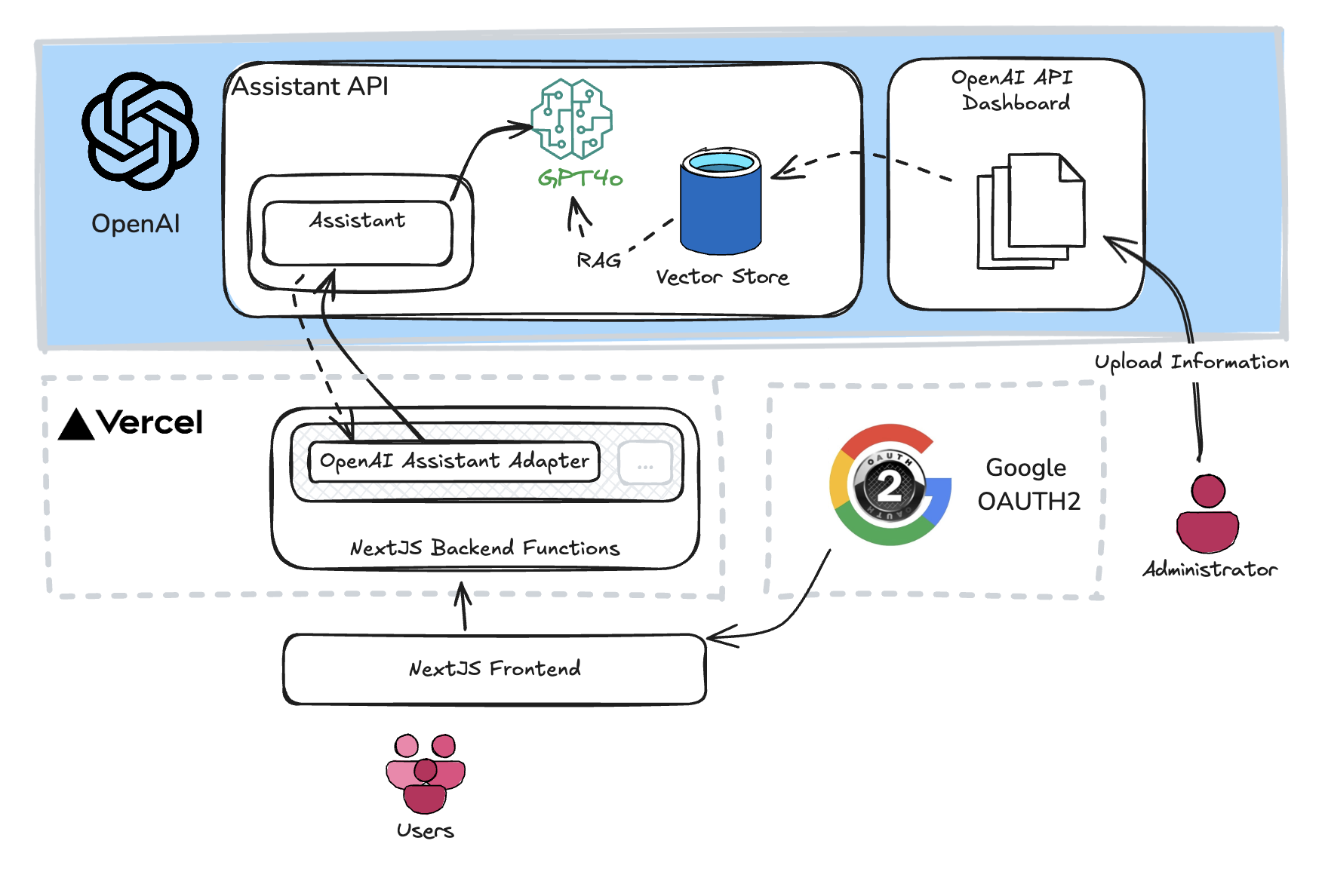
Core System Components
- Vercel: Hosts the Next.js frontend and backend, providing serverless functions and smooth deployments.
- Next.js Frontend & Backend: Manages the user interface and handles requests via serverless functions.
- Google OAuth2: Authenticates users for basic identification. This is used to restrict access to specific users and limit the number of sessions and interactions with the AI components, ensuring that platform costs remain under control.
- Vector Store: Stores CV data as embeddings, allowing the system to retrieve only the most relevant chunks for each query.
- AI Providers: Our implementation can work with multiple AI platforms (OpenAI, Flowise, etc.) thanks to our adapter pattern.
- Administrator: Responsible for uploading and updating CV documents.
- Users: End users interacting with the chat interface.
Detailed Workflow
Data Preparation
- CV Upload: Administrators use the OpenAI dashboard to upload CV-related documents.
- Chunking & Embedding: Uploaded CVs are broken into manageable sections (such as work history, projects, etc.) and converted into vector embeddings.
- Metadata Tagging: Each chunk is enriched with metadata (titles, dates, tags) for more precise retrieval later.
User Query Handling
- UI-Based Validation: When a user submits a question via the Next.js frontend, basic validations are performed directly in the UI to ensure the query meets the required format.
- API Access, Authorization & Limiting: The validated query is securely forwarded to the backend. This step leverages basic user identification provided by Google OAuth2 for authorization and includes API usage limiting to prevent high API consumption.
AI Invocation via the Adapter
- Standardized Request: The backend uses the adapter pattern to package the user’s query into a format compatible with the selected AI provider (OpenAI, Flowise, etc.).
- Platform Communication: The adapter handles provider-specific details, ensuring smooth and consistent AI invocation regardless of the underlying platform.
Retrieval Augmented Generation (RAG)
- Vector Similarity Search: Once the AI is invoked, the system computes an embedding for the query and searches the vector store to retrieve the most relevant CV chunks.
- Context Integration: The retrieved data is merged with the initial AI output, enriching the response with precise, context-specific details.
Reconstruct Answer with Moderation and Formatting
- Content Moderation & Formatting: While content moderation is planned for future iterations (requiring an additional API call or custom function in the assistant chain), the current setup focuses on reconstructing and polishing the answer for clarity.
- Display: The final, formatted response is delivered to the chat interface for the user.
Design Decisions
OpenAI Assistants Platform: The solution currently uses the OpenAI Assistants platform for this proof-of-concept. Although it’s still in Beta, it serves the purpose without causing any harm. However, I would not have selected it for a production solution due to its beta status. Zoom in on the Dashboard of OpenAI—it includes a built-in vector store that enables your agents to leverage RAG functionality with ease. This integrated environment is excellent for testing the assistant in the available playground, streamlining the development and iteration process.
Where to Go Next
Please revisit the main journey page for further insights into the motivations, challenges, and design decisions behind these technical details. Additionally, explore our AWS Bedrock Implementation page to see how we adapt our architecture to another leading AI platform. One exciting enhancement on the horizon is a streamed response approach. Unlike our current setup—which waits for the full response before sending it back—a streaming model would send partial results immediately for a more responsive experience. However, implementing streaming consistently is challenging due to differences among AI providers, with certain implementations (like Flowise’s current setup) making streaming nearly impossible.
In conclusion, OpenAI, as always, provides an excellent and extensive API toolset and—with its built-in RAG vector store—a really easy setup journey. This overview illustrates the careful balance between flexibility, efficiency, and scalability that underpins CV Chat’s design, making it a dynamic, multi-provider AI system poised for future technological advancements.