My Virtual CV Development Journey
February 18, 2025

Introduction
Over the past two years, I’ve been exploring how AI is reshaping software architecture and development. Along the way, I created a proof-of-concept called “CV Chat”—a tool that lets people engage in a conversation with a CV instead of just reading it. While this may sound like a novelty, many professionals know how frustrating it can be when recruiters reach out without really understanding your background. Sometimes it feels like they’ve read just the first line of your LinkedIn profile before contacting you.
This project isn’t meant to replace LinkedIn or recruiters. In my 30 years in IT, I’ve seen countless websites promising to solve these networking challenges, only to fade away over time. CV Chat simply explores how modern AI can transform the way we present and consume personal data. Thanks to new AI capabilities, it’s easier than ever to code solutions quickly—without being slowed down by the quirks of yet another new programming language.
Research
In designing CV Chat, I faced a technical challenge: how to effectively integrate a complete CV into an interactive chat interface that feels natural and responsive. As an IT architect, I needed a solution that could handle detailed, structured data while supporting dynamic conversations. The goal was to balance memory constraints, processing cost, and usability so that every detail of the CV was accessible without overwhelming the model. After some research and careful consideration, I identified three main approaches:
Prompt Engineering
Using prompt engineering means crafting one large message that includes the complete CV along with any other instructions the AI might need. Initially, this approach looked like the natural choice—it’s simple and direct. The idea is to create a comprehensive prompt such as: “You are an assistant. Here is the complete CV…” and then add any additional data needed for context. [NEW ADDITION] Here’s how it works in practice: When you feed the entire CV into the prompt, the model receives all of the information at once. This gives the AI a full view of your background and relevant details, so it can use that data to answer questions or engage in conversation accurately. However, because the prompt is so large, it comes with some significant downsides.
First, language models operate within a limited context window—meaning they can only process a certain amount of text at one time. A huge prompt risks filling up that space quickly, leaving little room for the conversation that follows. As the dialogue continues, parts of the initial prompt might be pushed out of the active memory, causing the model to lose important details about the CV. This is sometimes referred to as “context dilution.”
Second, larger prompts increase the computational cost. Each token (or word) you add requires extra processing, which can lead to higher operational costs and slower response times. It also makes the model’s output less efficient, as it has to sift through all the details every time it generates a response.
In summary, while prompt engineering by including the full CV and related data in one prompt ensures that all the necessary information is there from the start, it can also overwhelm the model’s capacity. This can lead to forgetting critical details as the conversation evolves and can make the system less cost-effective and slower in response. Balancing these trade-offs is key when deciding how to implement such a solution.
RAG (Retrieval Augmented Generation)
RAG takes a different approach by separating the data from the initial prompt. Instead of feeding the entire CV into one large message, the CV is divided into smaller, manageable chunks that are stored in a dedicated knowledge base or vector store. When a question comes in, the system retrieves only the most relevant pieces from that database and provides them to the model along with the query. [NEW ADDITION] In practice, this means that each section of the CV is first processed to create an embedding—a mathematical representation that captures the meaning of the text. When a user asks a question, the system computes an embedding for the query and searches the vector store to find the chunks that best match the query’s context. This targeted retrieval helps the model focus on the most relevant information without overloading its limited context window.
One of the biggest benefits of the RAG approach is that it keeps the input size small, preserving valuable space in the context window for ongoing conversation. The model only receives the necessary details for each specific query, which reduces the risk of context dilution and helps maintain accuracy over longer interactions. Moreover, because the data is stored externally, it’s easier to update or swap out information without having to rebuild the entire prompt.
However, implementing RAG comes with its own challenges. Setting up the vector store requires extra steps: you must break the CV into coherent sections, generate quality embeddings for each part, and ensure that the retrieval process is both fast and accurate. This adds a layer of technical complexity compared to simply using a giant prompt. There might also be a slight increase in response time due to the retrieval step, though the benefits of a more focused context often outweigh this drawback.
Overall, RAG offers a balanced solution by dynamically fetching only the relevant data needed for each interaction, making it a compelling alternative to the traditional prompt engineering approach.
Model Fine Tuning
Training the model directly with CV details can be very precise, but it’s also labor-intensive and tends to be tied to one specific person’s data. Fine-tuning means you take an existing AI model and further train it using your own text data—like a single CV or a set of CVs. In theory, this can produce very accurate and consistent answers because the model “absorbs” the content and style of your CV. But it’s also the most involved process: you need enough data to train it properly, you must handle different training steps (like single-turn or multi-turn dialogues), and you risk “overfitting” your model to one very narrow topic. If your CV changes or you want to switch to someone else’s CV, you might have to do the training all over again. This lack of flexibility was a major reason I steered away from it for a general-purpose tool.
Conclusion
Each approach has its advantages, but I opted for a more flexible path that can adapt to multiple CVs. After all, building a fully trained model just for myself felt like overkill. This endeavor taught me how AI can help solve everyday problems in a more interactive and user-friendly way—without needing to reinvent the wheel for every new idea.
Implementations
The chat interface or UI was developed decoupled from the actual AI implementations, as you may see and test for yourself the implementations can easily be switched within the interface. More information about each implementation can be found here:
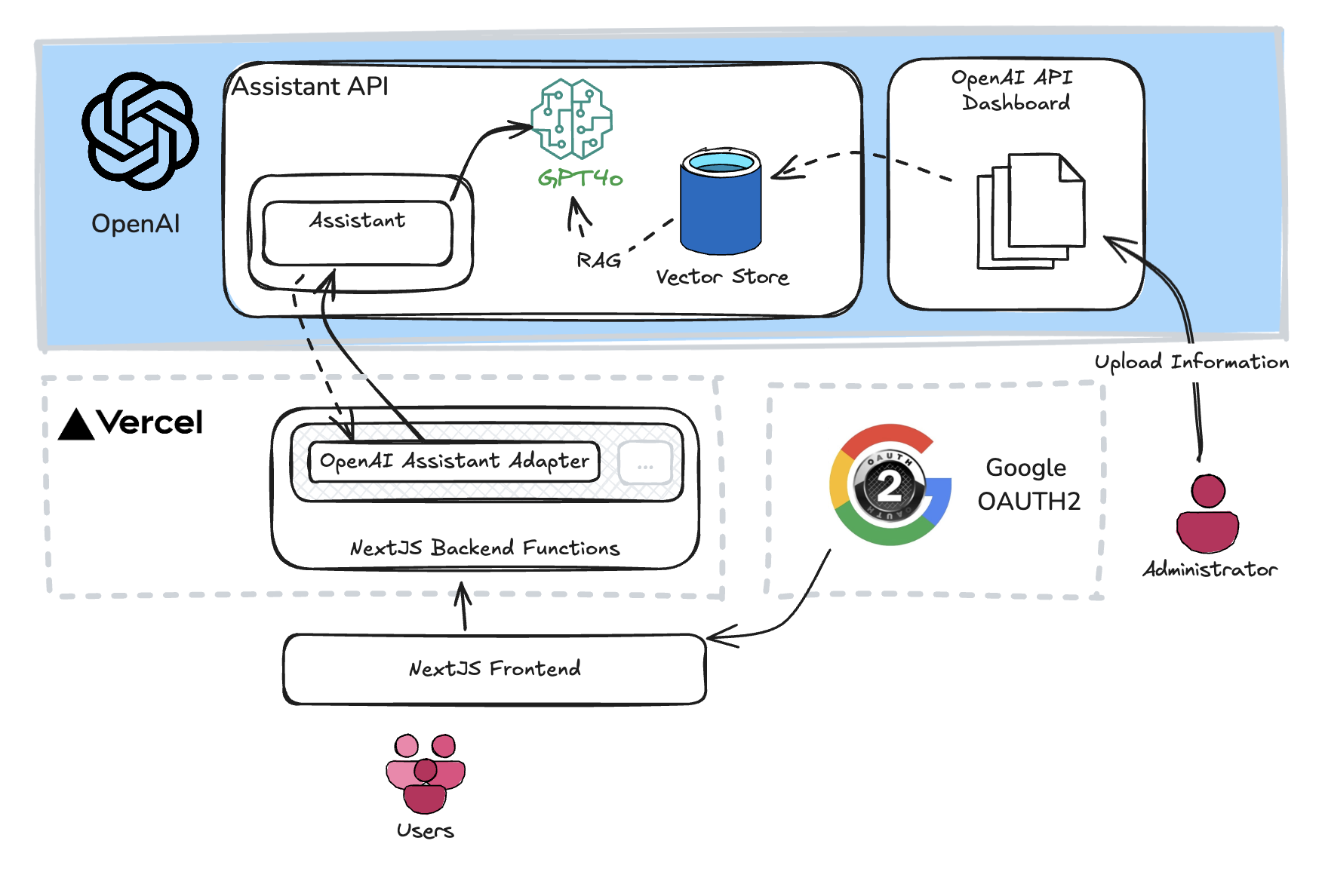
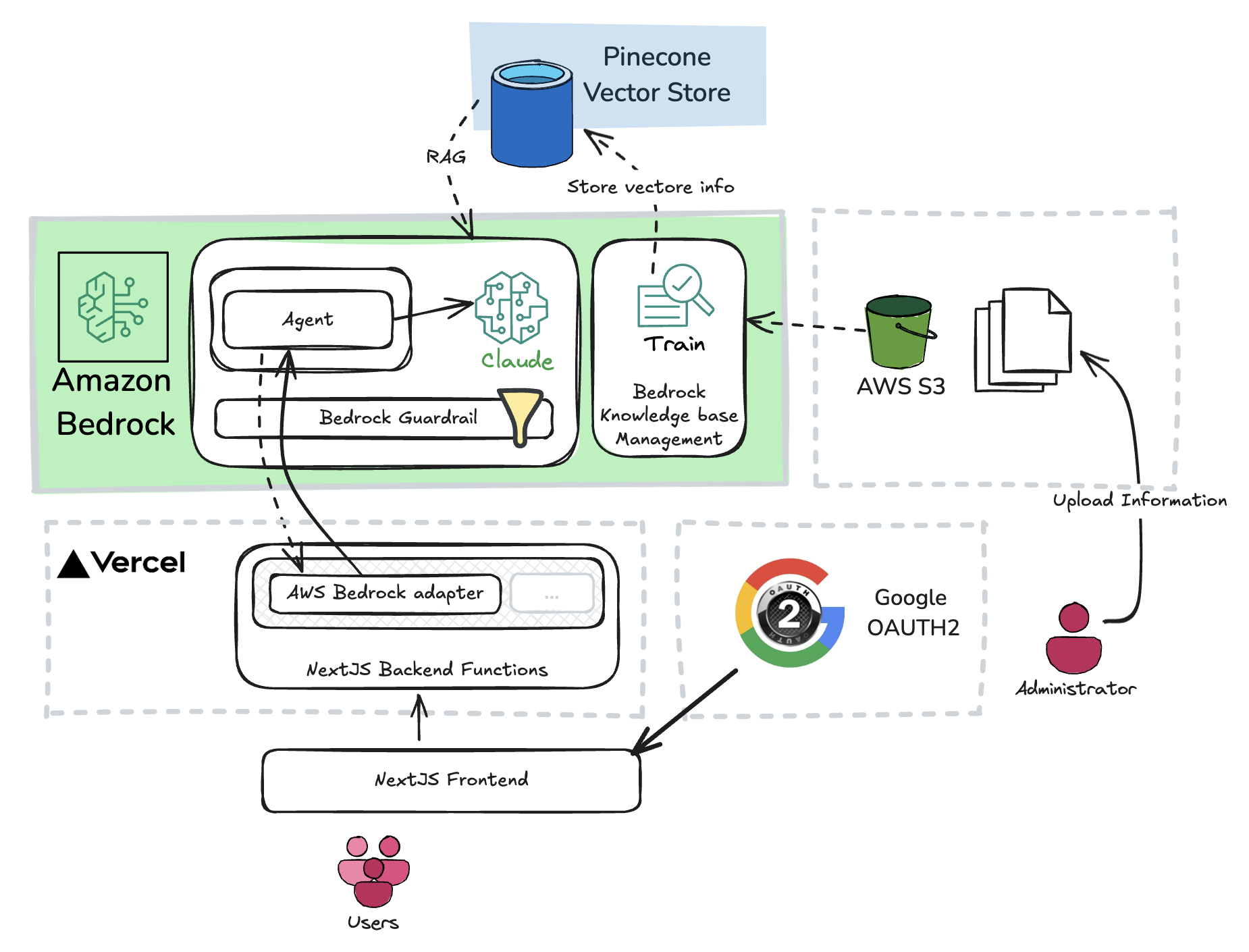
Addendum
To get CV Chat up and running, I started with a basic understanding of Large Language Models (LLMs) and how they handle text input. That was enough to build the first prototype, but maintaining the conversation context was the tricky part. The bigger the prompt, the harder it became for the model to keep track of all the details I’d fed into it—especially since CVs can get lengthy. The main lesson here was that LLMs work best when the prompt is kept concise and the model can fetch information as needed.
Multi tenant capable
Another factor that influenced my decision was the desire to allow multiple CV owners to use the same system. If I had chosen the fine-tuning route, I would have ended up with a model that was highly specialized for just one person, which defeats the purpose of building a more universal tool. By leaning into a retrieval-based approach, I can swap out or update documents easily, making the system applicable for different professionals who want to try something similar.
What's next
Creating CV Chat has also sparked ideas for future developments. For instance, integrating automated scheduling or hooking into a simple chatbot interface could streamline the entire job search process. Recruiters could quickly look up relevant details and follow up in real-time, without skimming through endless paragraphs on a resume or LinkedIn profile. Although it’s still early days for this proof-of-concept, it shows how quickly AI can transform mundane tasks—like reading someone’s CV—into a dynamic conversation that feels more personal and efficient.
In the end, AI isn’t magic; it’s another tool in the developer’s toolbox. But it’s a tool that helps us move faster and experiment with new interaction models. As technology continues to evolve, so do our opportunities to redefine how we share our professional stories. This “gadget” might not replace LinkedIn, but it offers a fresh perspective on what’s possible when we leverage the latest AI advancements.
Disclaimer
Though the system primarily serves as a proof of concept—or a playground—for AI research, it also provides a space to discuss interesting technologies. Because each AI implementation has received different levels of development and tuning, direct comparisons should be made with caution. With more refinement, any of these implementations could achieve similar or even superior performance.